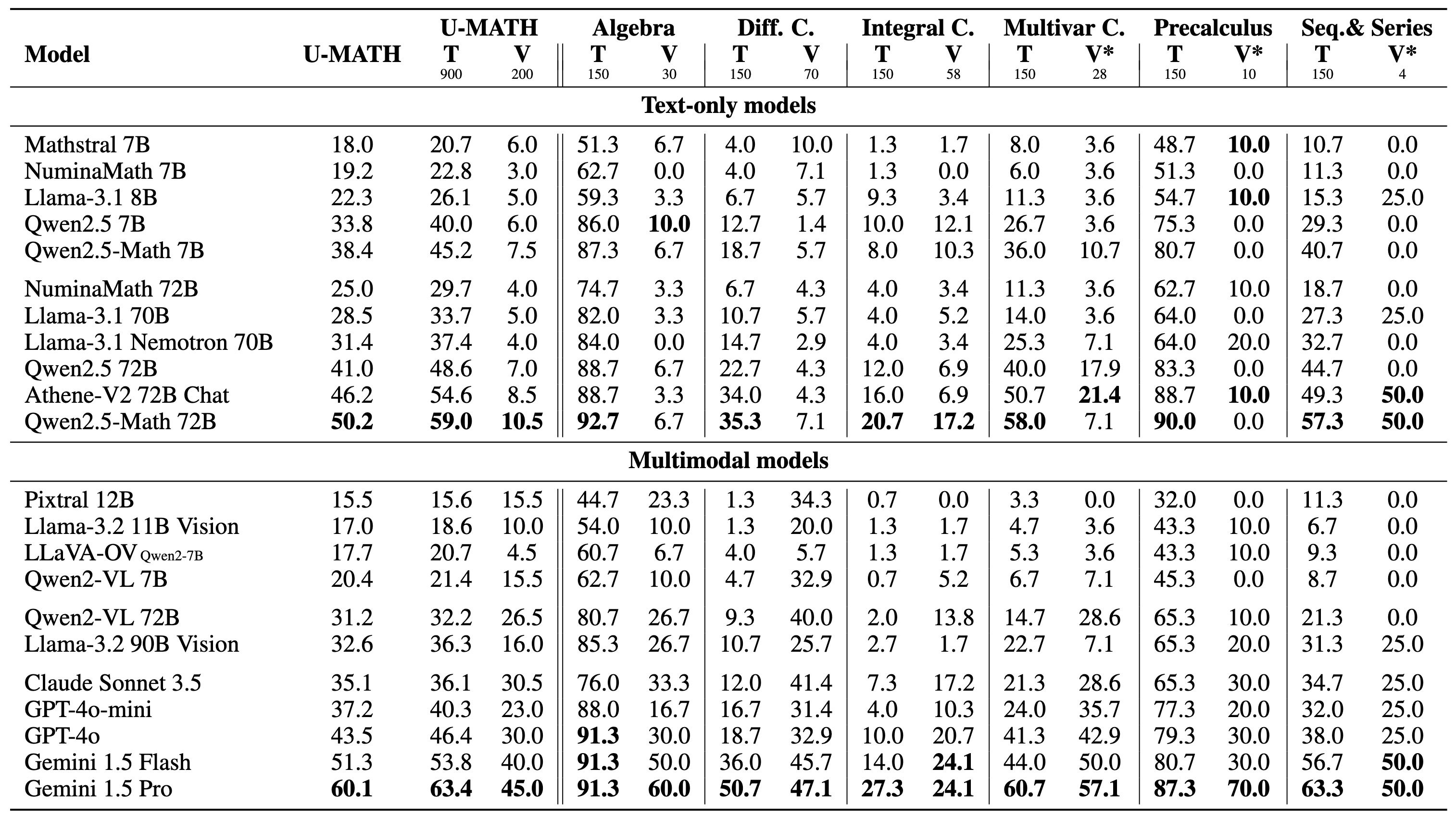
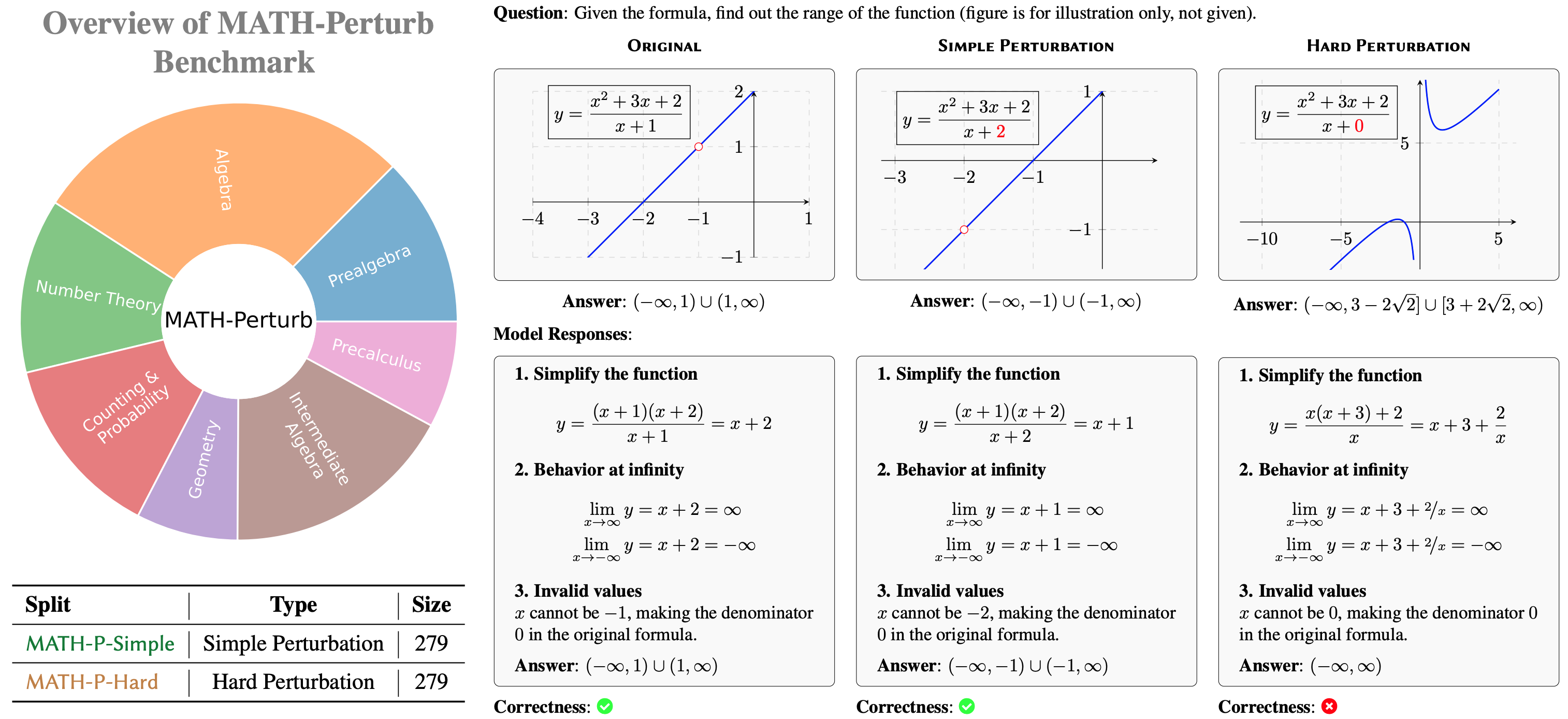
|
|
original poster
hbghlyj
posted 2025-5-16 02:13
GR.inc 的数学分类页面是一个涵盖广泛数学主题的资源库,收录了超过 83 万个可验证的问题和 10 万多个推理过程,适合从高中生到专业研究人员的不同层级用户使用。
该页面将数学内容细分为多个子领域,每个领域都包含大量相关问题和推理示例。以下是部分主要分类及其内容数量:
- 高中数学:307,606 个问题,41,104 个推理过程
- 数学竞赛:150,613 个问题,14,950 个推理过程
- 线性代数:23,763 个问题,276 个推理过程
- 微积分:21,595 个问题,1,759 个推理过程
- 几何学:14,758 个问题,363 个推理过程
- 统计学:14,361 个问题,177 个推理过程
- 数论:13,939 个问题,175 个推理过程
- 概率论:13,560 个问题,161 个推理过程
- 代数学:10,693 个问题,210 个推理过程
- 数学分析:9,997 个问题,197 个推理过程
此外,还包括拓扑学、复分析、组合数学、群论、抽象代数、范畴论等高级数学领域,每个领域均提供丰富的问题和详细的推理过程。
GR.inc 的数学页面支持中文界面,用户可以根据个人兴趣和学习需求,浏览、搜索并练习各类数学问题。
无论您是备战数学竞赛的学生,还是希望深入理解特定数学主题的研究人员,该平台都能为您提供系统化的学习资源和推理训练。 |
|